Table of Contents
Introduction
The Funnel system is a low-cost and easy to use solutions for systems that must handle extremely high volumes of data that is updated over time and that is queried at high rates. For example, ride hailing apps all receive massive volumes of updates for diver positions and status updates from vehicle drivers. This same data is also queried at high rates by customers, which have diverse criteria such as distance, car type, driver rating, etc. Funnel stands as a system that scales to take in this massive amount of data and serve queries at the same time. The system may be used in other domains as well, such as monitoring industrial equipment, stock values in finance, augmented reality gaming, or military applications.
System Overview
If physical constraints were of no concern, everyone would be using systems that are:
- Highly Performant : The volume of updates and requests would not impact system responsiveness.
- Safe and Persistent : Data would be written in persistent form that can be retrieved later without fear of errors or corruption.
- Flexible Queries : Data would be retrievable using arbitrary and expressive queries.
Traditional relational databases have flexible queries and are safe and persistent, however, they can struggle when it comes to handling extremely high volumes of data.
Traditional message queuing and publish/subscribe systems are highly performant and keep data safe and persistent, but their ability to query for data records is somewhat limited.
The Funnel system strikes a different balance. It focuses predominantly on current real-time data. Thus, it is highly performant and supports flexible queries, but for this is sacrifices the ability to query old historical data, which is instead left to other systems.
The Funnel system is composed of three different parts, named after the parts of a Funnel:
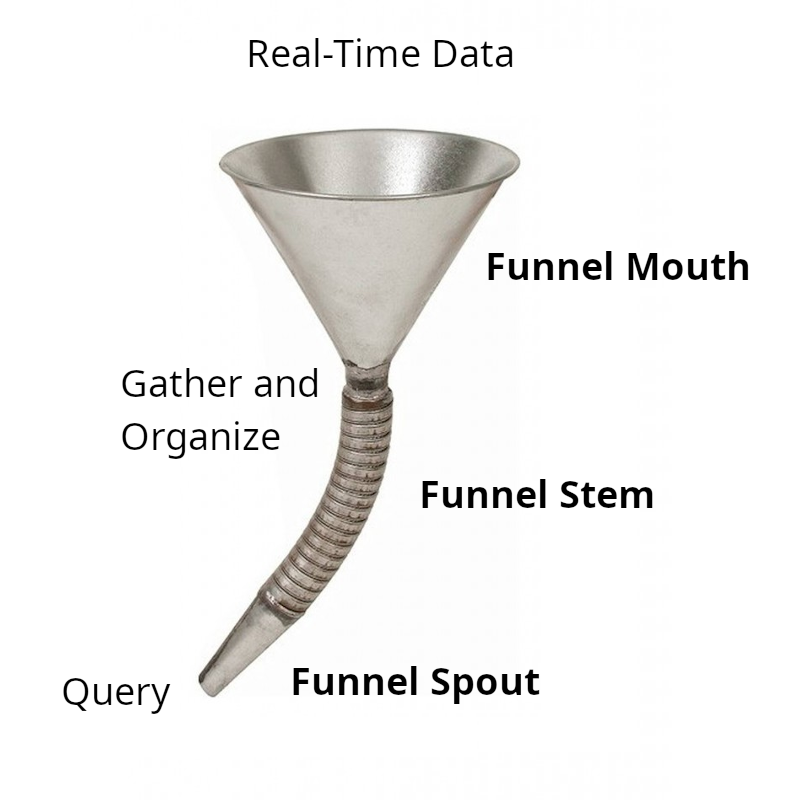
The main parts of the Funnel system are as follows:
- Funnel Mouth : Responsible for gathering massive volumes of individual data updates. It is horizontally scaled to keep up with larges numbers of connections from large numbers of data sources. It bundles data into batches to make further processing more efficient.
- Funnel Stem : Combines data bundles from the various Funnel Mouth instances and assures that each Funnel Spout instance can get access to the data it needs to execute queries.
- Funnel Spout : Highly efficient in-memory indexing and retrieval of data via queries.
The Funnel system treats real-time updating and querying for data as a top priority making trade-offs in other areas.
Funnel Integration Overview
The Funnel system integrates with your business by acting like a back-end service.
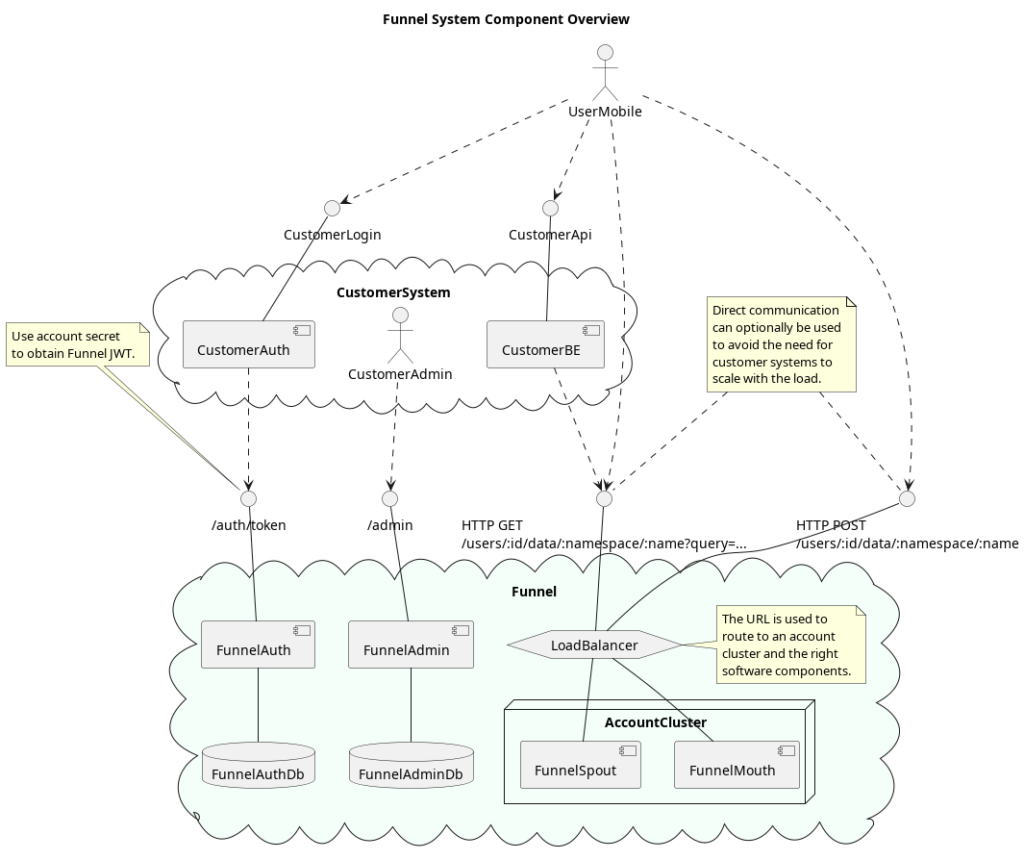
There are many possible ways to integrate with the Funnel system, but consider the following example for a taxi company with a mobile app.
- The Taxi Driver logs into TaxiCorp’s system using the TaxiCorp Driver Mobile App in order to start advertising their location and availability.
- TaxiCorp authenticates the user, and then uses its Funnel user to obtain a JWT token, which is then returned to the TaxiCorp Driver Mobile App.
- The TaciCorp Driver Mobile App starts to periodically advertise its location and status by sending data directly to Funnel using the JWT token.
- Customers can now log into their TaxiCorp Rider Mobile App, and likewise, TaxiCorp authenticates the user and uses its Funnel user to obtain a JWT token, which is returned to the TaxiCorp Rider Mobile App.
- The customer uses their location and preferences to search for a Taxi, and this query sent to and evaluated by Funnel to show Taxis on a map.
- The customer attempts to book a ride, and sends their request to TaxiCorp’s back-end system.
- TaxiCorp’s back-end system now must attempt to book a ride with a TaxiDriver, and it too may use Funnel to search for possible Taxis to complete the user’s request.
Concepts
Apache Avro Schemas
Funnel can take read user-defined schema files that describe the data to be uploaded and queried. These schema files must be formatted as Apache Avro Schema files. These files are based upon JSON, but the schema specification follows regular rules that allow it to describe and validate data.
At its heart, Apache Avro Schema files follow a relatively simple format that has a great deal of flexibility. An individual Schema can take one of three forms:
// A simple string, referencing a type.
"string"
// An array, which is a union of different types.
["null", "string"]
// An object describing the type.
{
"type": schemaType,
// ...attributes
}Code language: JSON / JSON with Comments (json)Primitive Schema Types
A few Schema types are already pre-defined as part of the Avro specification, namely:
null: no valueboolean: a binary value, either “true” or “false”int: a 32-bit signed integerlong: a 64-bit signed integerfloat: single precision (32-bit) IEEE 754 floating-point numberdouble: double precision (64-bit) IEEE 754 floating-point numberbytes: a sequence of 8-bit unsigned bytesstring: a Unicode character sequence
These types, known as Primitive Types, do not have to be defined by the user, and may freely be referenced by name.
Complex Schema Types
In Apache Avro, a few Complex Types exists, whose primary purpose is to let you mix, match, and combine primitive and other complex types.
Records
The Avro type “record” is conceptually equivalent to JSON Objects. In fact, in JSON format, they are represented as Objects (in binary, they are represented as an ordered list of field data). Each field in a record consists of at least a name and a type, and not every type is required to be identical.
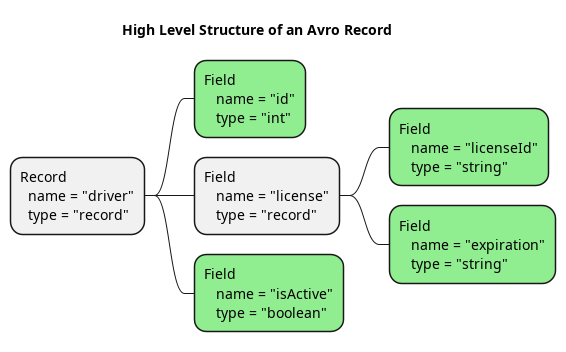
As the image above illustrates, a record can even contain other records. In Avro Schema format, the image above would be defined as follows:
{
"type": "record",
"name": "driver",
"namespace": "taxis",
"fields": [
{ "type": "int",
"name": "id"
},
{ "type": "record",
"name": "license",
"fields": [
{ "type": "string",
"name": "licenseId"
},
{ "type": "string",
"name": "expiration"
}
],
},
{ "type": "boolean",
"name": "isActive"
}
]
}Code language: JSON / JSON with Comments (json)The following JSON object would be compatible with the Avro Schema above:
{
"id": 23,
"license": {
"licenseId": "D121151",
"expiration": "2025/10/03"
},
"isActive": true
}Code language: JSON / JSON with Comments (json)Funnel Concepts
Funnel Service Users
After you have created a contract agreement with Funnel-Labs.io, a Funnel Service User will be created that you may use for your business systems. This Funnel Service User is considered to be the owner of resources you define, such as Funnel Schemas (described further below).
Funnel Schemas
The Funnel system is built to allow users to define their data formats using Apache Avro. The format that you define for your business will control the update and validation of data by the Funnel system as well as define the kinds of queries that may be used to search for that data.
In our examples that follow, we will refer to the following Avro Schema:
{
"type": "record",
"namespace": "funtaxi", // (1) Used in URLs
"name": "Driver", // Used in URLs
"fields": [
{
"name": "id",
"type": "string"
},
{
"name": "status",
"type": {
"type": "enum",
"name": "Status",
"symbols": ["INACTIVE", "ACTIVE"]
},
},
{
"name": "rating",
"type": "int",
},
{
"name": "coord",
"type": {
"type": "record",
"name": "Coordinate",
"fields": [
{"name": "latitude", "type": "double"},
{"name": "longitude", "type": "double"}
]
}
}
]
}Code language: JSON / JSON with Comments (json)While this may look like a normal Avro schema, each of the fields has special meaning to the Funnel system.
(1) The fields “name” and “namespace” are used to group access to your data formats in Funnel. For example, if you define a Schemas with “namespace” set to “taxifleet” and “name” set to “MyTaxi”, then the URLs needed to access that data will be at https://api.funnel-labs.io/user/myUser/taxifleet/MyTaxi. The HTTP POST method will upload new data and the HTTP GET method will be used to issue queries.
Choosing a Primary Key with Funnel
According to the Avro Specification, Schema files may have more than just the predefined attributes like "name", "type", and "fields". Additional fields simply exist as additional data, and these fields are not used to either serialize or de-serialize data. Funnel uses its own set of fields to configure itself.
The first Funnel-specific field is named "idx_primary". This attribute is used by funnel to determine which field will be used to uniquely identify records that you upload. When you upload two records that share the same primary key, the second upload is considered to be an update of the value rather than an entirely new record.
In this example, we will add the "idx_primary" attribute to the "id" field.
{
"type": "record",
"namespace": "funtaxi",
"name": "Driver",
"fields": [
{
"name": "id",
"type": "string",
"idx_primary": true // Added primary key
},
// ...Code language: JSON / JSON with Comments (json)To clarify the impact of a primary key, imagine that we upload the following records:
{ "id": "D1001", "status": "ACTIVE"}
{ "id": "D1002", "status": "ACTIVE"}
{ "id": "D1001", "status": "INACTIVE"}Code language: JSON / JSON with Comments (json)After these updates, Funnel will only have 2 records in memory, “D1001” (INACTIVE) and “D1002” (ACTIVE). The third upload is interpreted to be an update of the record “D1001”, because the primary key defines which records are unique.
The primary key can also be used to retrieve the most recent version of the record. This is done by using a URL of the form: FUNNEL_SPOUT_URL/<namespace>/<name>/<primaryKey>
For example:
curl -X GET https://api.funnel-labs.io/users/myUser/data/funtaxi/Driver/D1001Code language: JavaScript (javascript)Accessing your data using only the primary key like this is a nice convenience, but the power of Funnel is actually in its query language. While details about the query language will be described later, it is worth stating now that the record can also be accessed via a query. To retrieve this same record using a query, the command would be as follows:
curl -X GET https://api.funnel-labs.io/users/myUser/funtaxi/Driver?query=id="D1001“
Index Types
By default, the primary key has a type called “equality”. As the name suggests, this index can be used for equality operations, such as id = "D1001". But what is an index?
An index is an internal data structure that organizes data records according to a given value, so that they may be quickly located using that value. The index may be implemented using a hash table, a sorted list, a Red-Black Tree or something else. The most important thing about indexes is that they must allow a record to be found faster than it would take to look through the list of data itself.
In Funnel, there are three index types:
- equality : The fastest index type, but it only supports query operations like “=” and “IN”. It is also the default index type, if not specified, for
idx_primaryfields. - comparing : Slightly slower than the “equality” type, but it supports operations like “>”, “=”, “<“, and “IN”.
- spatial : A fast index type dedicated to the processing of geographic locations and coordinates, which supports the “WITHIN … OF (…, …)” query operation.
To be able to query your data records by the values of their fields, one must add an index for that field. This is done by adding an idx_type attribute to your schema for each field to be indexed. The value of this attribute should be one of "equality", "comparing", or "spatial".
We can update our schema in this example to allow each field to be used in queries.
{
"type": "record",
"namespace": "funtaxi",
"name": "Driver",
"fields": [
{
"name": "id",
"type": "string",
"idx_primary": true // "id" is used to uniquely identify drivers.
},
{
"name": "status",
"type": {
"type": "enum",
"name": "Status",
"symbols": ["INACTIVE", "ACTIVE"]
},
"idx_type": "equality" // Enables "=" queries on status.
},
{
"name": "rating",
"type": "int",
"idx_type": "comparing" // Enables "<", "=", and ">" queries on rating.
},
{
"name": "coord",
"type": {
"type": "record",
"name": "Coordinate",
"fields": [
{"name": "latitude", "type": "double"},
{"name": "longitude", "type": "double"}
]
},
"idx_type": "spatial" // Enables "WITHIN" queries on coord.
}
]
}Code language: JSON / JSON with Comments (json)Query Language
Query Clauses
A simple query that involves a single field and a single operation is known as a “query clause”. Example clauses include:
- rating > 25
- id = “D1001”
- coord WITHIN 2 km of (21.23, 45.12)
Simple comparison clauses are in the format:
<field> <operation> <argument>Code language: HTML, XML (xml)Thus, the clause rating > 25 has a field of “rating”, an operation of “>”, and an argument of “25”. The field is the name of the record field that has an associated idx_type or idx_primary attribute. The operation consists is one of “=” (equality), “<” (less than), or “>” (greater than). The argument is the value that the field will be compared to, using the selected operation.
When a clause is evaluated, it will produce a set of records, Drivers in this example, which satisfy the restrictions of the query. This set of records is actually what is included in the HTTP Response body that is returned in response to a query HTTP Request.
A special syntax is created for within clauses in order to simplify spatial queries.
<field> WITHIN <distance> <units> OF ( <latitude>, <longitude> )
Typical units are “km” for kilometers and “m” for meters.
Logical Chains
The query language of Funnel can best be understood by comparing it to arithmetic. Consider the following arithmetic expression:
3 + 2 x 4
The value of this expression is 11, it is the equivalent of 3 + ( 2 x 4 ) and not ( 3 + 2 ) x 4. This is because in arithmetic expressions, there is a precedence of operations, with multiplication and division having higher precedence than addition and subtraction.
In Funnel, as well as SQL and most other programming languages, the AND operation is treated as higher precedence than OR. Thus, you can think of AND as being evaluated in the same way that multiplication and division are, while OR is evaluated the same way addition and subtraction are.
The major logical operations supported by funnel are AND and OR.
- AND : When evaluating
clause1 AND clause2, a record is included in the result only if it is in both clause1 as well as clause2. - OR : When evaluating
clause1 OR clause2, a record is included in the result if it is in clause1, clause2, or both clause1 and clause2.
Just as one can add 3 to 2 x 4, one can also combine logical chains in a similar manner. Consider the following example logical chains with clauses and other logical chains.
- id = “D1002” OR rating > 25 AND coord WITHIN 2 km OF (12.34, 0.123)
Returns drivers if either theiridhas value “D1002” or the driver has both a rating above 25 and is within 2km of the coordinate (12.34, 0.123). - id = “D1002” AND rating > 25 OR coord WITHIN 2 km OF (12.34, 0.123)
Returns driver “D1001” only if he also has a rating above 25 as well as all drivers within 2km of the coordinate (12.34, 0.123).
Parenthesis
One can override the normal operator precedence by including parenthesis in your query.
- ( id = “D1002” OR rating > 25 ) AND coord WITHIN 2 km of (12.34, 0.123)
This query returns drivers who are within the coordinate (12.34, 0.123) and either have a rating above 25 or have anidof “D1002” (Driver “D1002” is near and dear to our hearts, regardless of his rating.)
Funnel System Security
In order to use the Funnel system, one must have a Funnel user account. This user account and its credentials will be used to secure access to your data, making sure that only those authorized by your back-end services may provide updates to your data or query your data.
The mechanism of securing access is based on OpenID Connect (OIDC). OIDC is an implementation of the standards described in OAuth 2.0.
For those who are not familiar with these protocol, allow a brief summary of what they are:
- OAuth outlines a way in which computer systems may be granted access to resources that a user owns, without having access to that user’s secret credentials, e.g. their password, fingerprints, etc.
- OpenID Connect defines a specific API for entering credentials securely and obtaining secure proof of permission to access resources owned by users.
- The proof of permissions to access resources is defined as an Access Token, which is represented in JSON Web Token (JWT) format. This is a data structure that contains the user’s identity, the categories of permissions they have access to (called “scopes”).
- JWTs also contain a narrow time window in which they are valid. This protects them from being captured from historic data or replaying user traffic in order to steal system access.
- JWTs are in a format that is protected by a digital signature. This means that any attempt to modify the JWT in any way will cause systems to reject it. This is done using asymmetric encryption; the information needed to read and verify a signature is public and anyone may access it, but the information needed to write a signature is secret and only known by the authentication server.
In order to minimize the risk of an Access Token being stolen and misused, they typically have a very short duration in which they are considered to be valid. Systems that are accessing resources on behalf of the user would be forced to frequently prompt their users for credentials unless there was a way to indicate that access is still needed and should be considered valid.
This problem is solved via the use of a Refresh Token. In a nutshell, you can think of a Refresh Token as a temporary password that has a longer lifetime than the Access Token. If a system is still active and the user is still interacting with the system, the Refresh Token can be offered as credentials so that a new Access Token should be issued to the service. Refresh Tokens are kept secure by configuring a few properties of theirs:
- The total time in which a Refresh Token is considered valid. This is usually in hours, while Access Tokens are only valid for minutes.
- The idle time between uses of a Refresh Token after which it is considered invalid, and the user must enter their credentials to gain system access.
For example, a Refresh Token may in theory last up to 10 hours, but if it is not used every 10 minutes during that 10 hour period, it will expire early.
Account Creation
Creating an account consists of following a standard OpenID Connect flow using the Identity and Access Manager of Funnel-Labs.io.
Start by either clicking the “Sign-Up” link on the main website, or going directly to the API web admin page at https://api.funnel-labs.io/web/index.html.
This link will allow signing in to an existing account or registering a new account. The signup process is straight forward:
If you do not yet have an account, simply click the “Register” link at the bottom of the dialog.
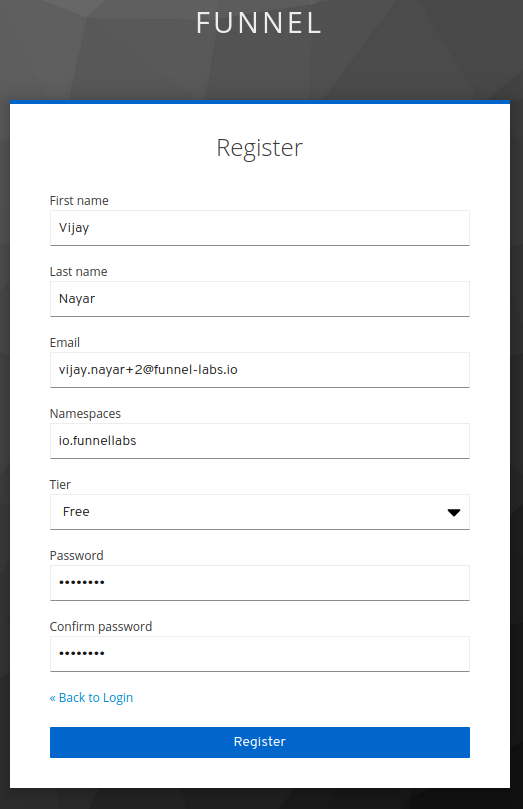
The signup form asks for a your name and email. The email is used as the account name, and used used when logging in.
After registration, an email will be sent to the one that was entered, which will contain a link that must be clicked before the account can be used.
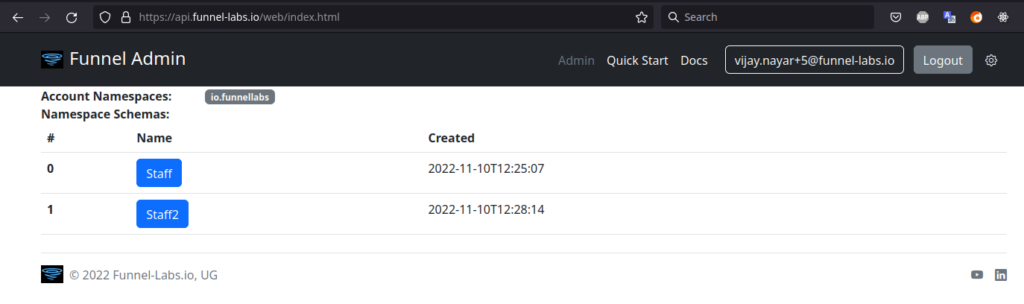
Admin Web Interface
After creating an account, a very simple web interface will be presented at https://api.funnel-labs.io/web/index.html. It allows one to briefly view and edit the account settings, including the account’s namespace. However, the primary way to interact with the Funnel System is via the REST Interface described below.
Account Tiers
Accounts that are created using the sign-up link begin in the “Free Tier” and are completely without cost to users. The main restriction on Free Tier accounts is that they are limited in terms of the number of requests they can make per minute. Such accounts are suitable for exploration and low usage cases.
For customers that wish to scale up their usage, reach out to accounts@funnel-labs.io and describe your usage needs.
Funnel System REST Interface
Interface: Obtaining Access/Refresh Tokens
The Funnel system adheres to OpenID Connect and OAuth2.0 specifications for its interfaces, which provide additional documentation for the specific meaning of the fields.
- Protcol: HTTPS
- Method: POST
- Host: https://auth.funnel-labs.io
- Path: /auth/realms/funnel/protocol/openid-connect/token
- Request Headers:
- Content-Type: application/x-www-form-urlencoded
- Request Body:
client_id=service&grant_type=password&username=myUser&password=myPassword - Request Body Parameters:
- myUser – {string} The name of the Funnel User created for your company.
Note: This must be URL escaped, so if your email contains a “+”, replace it with “%2B”. - myPassword – {string} The secret password for your Funnel User, which should be protected carefully.
- myUser – {string} The name of the Funnel User created for your company.
- Response Headers:
- Content-Type: application/json
- Response Body:
{
// @type {string} The JWT token encoded in base64, this should be saved for future requests.
“access_token”: “eyJh…7dTg”,
// @type {number} The number of seconds for which the access_token will be accepted.
“expires_in”: 300,
// @type {number} The number of seconds for which the refresh_token will be accepted.
“refresh_expires_in”: 1800,
// @type {string} The OAuth 2.0 refresh token, used to obtain new access tokens.
“refresh_token”: “eyJh…vhZ4”,
// @type {string} The authentication schema, which is used with the Access Token.
“token_type”: “Bearer”,
// @type {string} The space-separated list of permissions that the Access Token has.
“scope”: “funnel-mouth funnel-spout”
}
Example request with curl:
$ curl -s -X POST https://auth.funnel-labs.io/auth/realms/funnel/protocol/openid-connect/token \
-d "client_id=service&username=demo&password=abcd1234&grant_type=password"
$ ACCESS_TOKEN=$(curl -s -X POST https://auth.funnel-labs.io/auth/realms/funnel/protocol/openid-connect/token \
-d "client_id=service&username=demo&password=abcd1234&grant_type=password" | jq -r '.access_token')Code language: JavaScript (javascript)Interface: Uploading/Updating a Schema
In order to upload data in a format consistent with a schema and to submit queries for data, one must first upload your schema into the Funnel system.
- Protocol: HTTPS
- Method: POST
- Host: https://api.funnel-labs.io
- Path: /admin/schemas
- Request Headers:
- Authorization: Bearer ACCESS_TOKEN
- Request Header Parameters:
- ACCESS_TOKEN – {string} The JWT Access Token retrieved from the “access_token” field of
/auth/realms/funnel/protocol/openid-connect/token.
- ACCESS_TOKEN – {string} The JWT Access Token retrieved from the “access_token” field of
- Response Status:
- 200 OK – The schema was successfully added or updated.
- 400 BAD REQUEST – The schema was syntactically invalid.
- 401 UNAUTHORIZED – The given ACCESS_TOKEN could not be authenticated.
- 403 FORBIDDEN – The authenticated user does not have permission to update a schema in the given namespace.
- Response Headers:
- Content-Type: text/plain
- Response Body:
OK
Example request with curl:
# The file in "avro/user.avsc" contains the schema we want to upload.
$ curl https://api.funnel-labs.io/admin/schemas -X POST \
-d '@avro/user.avsc' -H 'Content-Type: application/json' \
-H "Authorization: Bearer $ACCESS_TOKEN"
OK
Interface: Reading a Schema
Schemas are owned by a user account, are grouped into namespaces, and have individual names. This endpoint allows the currently used version of a schema to be read for diagnostics or utility purposes.
- Protocol: HTTPS
- Method: GET
- Host: https://api.funnel-labs.io
- Path: /admin/schemas/namespace/name
- Path Parameters:
- namespace – {string} This must match the “namespace” field of the Schema.
- name – {string} This must match the “name” field of the Schema.
- Request Headers:
- Authorization: Bearer ACCESS_TOKEN
- Request Header Parameters:
- ACCESS_TOKEN – {string} The JWT Access Token retrieved from the “access_token” field of
/auth/realms/funnel/protocol/openid-connect/token.
- ACCESS_TOKEN – {string} The JWT Access Token retrieved from the “access_token” field of
- Response Status:
- 200 OK – Success when both authorized and the data is correctly formatted.
- 400 BAD REQUEST – The query is syntactically invalid.
- 401 UNAUTHORIZED – The JWT token could not be authenticated.
- 403 FORBIDDEN – The schema or user account being accessed is not permitted.
- 500 INTERNAL SERVER ERROR – A temporary error sometimes visible during maintenance.
- Response Headers:
- Content-Type: application/json
- Response Body:
{
// An AVRO Schema in JSON
"namespace": "funnel",
"name": "Update",
"type": "record",
"fields": [
{"name": "id", "type": "string", "idx_primary": true},
// ...
]
}
Example request with curl:
$ curl -X 'GET' 'https://api.funnel-labs.io/admin/schemas/funnel/Update' \
-H "Authorization: Bearer $ACCESS_TOKEN"
{
"namespace", "funnel",
"name": "Update",
"type": "record",
"fields": [
{
"idx_primary": true,
"name": "id",
"type": "string"
},
{
"idx_type": "equality",
"name": "status",
"type": {
"name": "Status",
"namespace": "funnel",
"symbols": [
"INACTIVE",
"ACTIVE"
],
"type": "enum"
}
},
...
}Code language: JavaScript (javascript)Interface: Updating Data for a Schema
Schemas are owned by a user account, are grouped into namespaces, and have individual names. This endpoint allows data that is compliant with an Avro Schema to be inserted/updated in the Funnel system.
- Protocol: HTTPS
- Method: POST
- Host: https://api.funnel-labs.io
- Path: /users/userAccount/data/namespace/name
- Path Parameters:
- userAccount – {string} The user account owning the Schema.
- namespace – {string} This must match the “namespace” field of the Schema.
- name – {string} This must match the “name” field of the Schema.
- Request Headers:
- Content-Type: application/json
- Authorization: Bearer ACCESS_TOKEN
- Request Header Parameters:
- ACCESS_TOKEN – {string} The JWT Access Token retrieved from the “access_token” field of
/auth/realms/funnel/protocol/openid-connect/token.
- ACCESS_TOKEN – {string} The JWT Access Token retrieved from the “access_token” field of
- Request Body:
JSON that is compatible with the corresponding Avro Schema. - Response Status:
- 200 OK – Success when both authorized and the data is correctly formatted.
- 400 BAD REQUEST – The request body is incorrectly formatted.
- 401 UNAUTHORIZED – The JWT token could not be authenticated.
- 403 FORBIDDEN – The schema or user account being accessed is not permitted.
- 500 INTERNAL SERVER ERROR – A temporary error sometimes visible during maintenance.
Example request with curl:
$ curl -d '{
"id": "bee",
"status": "ACTIVE",
"age": 41,
"coord": { "latitude": 3.21, "longitude": 4.32 } }' \
-H 'Content-Type: application/json' \
-H "Authorization: Bearer $ACCESS_TOKEN" \
https://api.funnel-labs.io/users/demo/data/funnel/Update
OKCode language: PHP (php)Interface: Querying Data for a Schema
Schemas are owned by a user account, are grouped into namespaces, and have individual names. This endpoint allows data that is compliant with an Avro Schema to be inserted/updated in the Funnel system.
- Protocol: HTTPS
- Method: GET
- Host: https://api.funnel-labs.io
- Path: /users/userAccount/data/namespace/name?query=queryString
- Path Parameters:
- userAccount – {string} The user account owning the Schema.
- namespace – {string} This must match the “namespace” field of the Schema.
- name – {string} This must match the “name” field of the Schema.
- Query Parameters:
- queryString – {string} A query on the data, described in Query Language.
- Request Headers:
- Authorization: Bearer ACCESS_TOKEN
- Request Header Parameters:
- ACCESS_TOKEN – {string} The JWT Access Token retrieved from the “access_token” field of
/auth/realms/funnel/protocol/openid-connect/token.
- ACCESS_TOKEN – {string} The JWT Access Token retrieved from the “access_token” field of
- Response Status:
- 200 OK – Success when both authorized and the data is correctly formatted.
- 400 BAD REQUEST – The query is syntactically invalid.
- 401 UNAUTHORIZED – The JWT token could not be authenticated.
- 403 FORBIDDEN – The schema or user account being accessed is not permitted.
- 500 INTERNAL SERVER ERROR – A temporary error sometimes visible during maintenance.
- Response Headers:
- Content-Type: application/json
- Response Body:
[
// @type {object} Data objects according to the Avro Schema in use.
{ },
...
]
Example request with curl:
$ curl -H "Authorization: Bearer $ACCESS_TOKEN" \
'https://api.funnel-labs.io/users/demo/data/funnel/Update?query=age>3'
[
{"id": "myFleet-0", "status": "INACTIVE", "age": 22, "coord": {"latitude": 52.496, "longitude": 13.3282}},
{"id": "myFleet-28", "status": "INACTIVE", "age": 22, "coord": {"latitude": 52.5078, "longitude": 13.3338}},
...
]Code language: JavaScript (javascript)