Assessing Performance of Network Systems
Table of Contents
- Introduction
- A System is as Strong as its Weakest Link
- Levels of Testing
- Performance Testing
- Summary
Introduction
As development of software services moves from a local development environment environment to a staging or production environment, a common concern that arises is to know the limits of what the system can handle in terms of performance. Knowledge of what your system can handle is useful for several reasons:
- Performance numbers are often desired for marketing purposes if the service being deployed is one that will be used in business-to-business use cases.
- Performance numbers often can give a prediction of how many customers the system can handle in business-to-customer use cases.
- The performance numbers can be used to help estimate operating costs for systems that have the ability to horizontally scale or vertically scale.
- Performance numbers are essential for identifying flaws in software that cause it to perform significantly slower than initially intended. E.g. it is far better to discover early rather than during an emergency that your software was only using a single thread and that fancy expensive 16 core CPU you are using is going to waste.
The rationale for performance testing is identical to that of unit and integration testing. Nobody actually writes bugs on purpose, but as the phrase goes:
To err is human, to forgive, divine.
– Alexander Pope, An Essay on Criticism

Unfortunately the writers of software are human, and they do indeed make mistakes. However, our customers are not divine, thus they may not forgive those mistakes.
A System is as Strong as its Weakest Link
To understand system performance, one must always keep in mind some classic wisdom:
The chain is only as strong as its weakest link, for if that fails the chain fails and the object that it has been holding up falls to the ground.
– Thomas Reid, Essays on the Intellectual Powers of Man

- A multi-threaded application running an inefficient O(n3) algorithm may not deliver the gains promised through the work on multi-threading.
- An efficient O(n) algorithm that can only run in a single thread will not benefit much from being deployed on a power 16 core CPU.
- An efficient O(n) algorithm that is also multi-threaded means nothing if it requires more RAM than the system has.
- A super efficient and fast system means nothing if the disk it depends on for persistent storage is slow.
- And the system that is as efficient as possible in every way you can think of is still not performant if the network connection between yourself and your customers is slow.
These various reasons for performance problems illustrate the importance of testing in the specific environment in which your system will actually run. There is no magic guide that will tell you what will cause a system to perform badly, it depends heavily on deductive reasoning and knowing what the possible bottlenecks of system performance are.

Common reasons for performance bottlenecks include:
- Inefficient Algorithms: Assessing the performance of a system depends in part on knowledge of how well a system SHOULD perform. Sometimes a complex problem has no way around the fact that the problem itself is inherently difficult. However, a simple transformation of data should run with linear complexity compared to the input. More complex problems, like computing bus routes to cover various bus stops, should be recognized as a Traveling Salesman problem, thus the complexity should at most be polynomial and not exponential.
- Sequential vs. Parallel Computation: When your software is executing on a CPU that can run multiple threads of execution in parallel, significant gains can be achieve by breaking problems down into independent blocks of logic that can execute in parallel, resulting in less wall-clock time being used, which translates into faster response times and higher throughput. However, multi-threading should not be seen as a panacea, because context switching imposes significant costs. If a program inappropriately demands far more threads than physical cores on the CPU that can execute them, performance can actually drop precipitously, with more time being used on context switching than the actual execution of code.
- Disk/Memory Access: The time it takes to get access to information varies exponentially on where the information comes from. If getting data from the CPU cache is akin to getting an item from your room, getting data from disk is akin to flying to Jupiter (assuming you are using a solid-state drive). There are several indirect reasons why your program may end up reading from disk, the most common being retrieving data from a database or because your program is too big to fit into physical ram, and thus page faults cause parts of your program to swap between virtual and physical memory.
- Network Access: Even in the most optimal environments inside a data-center, such as an AWS Availability Zone, add latency. It simply takes time for information to go from the CPU, to RAM, to be accessed via DMA by a network card, to travel across ethernet cables, and then be received by another computer which does all this in reverse. Even within a single data-center (such as an AWS Availability Zone), 1ms to 2ms is common. When communicating across AWS Availability Zones, this goes up to 10ms if one includes load-balancers and other intermediaries. Latency with a user on a 3G cellular network can be between 100ms and 500ms.
Levels of Testing
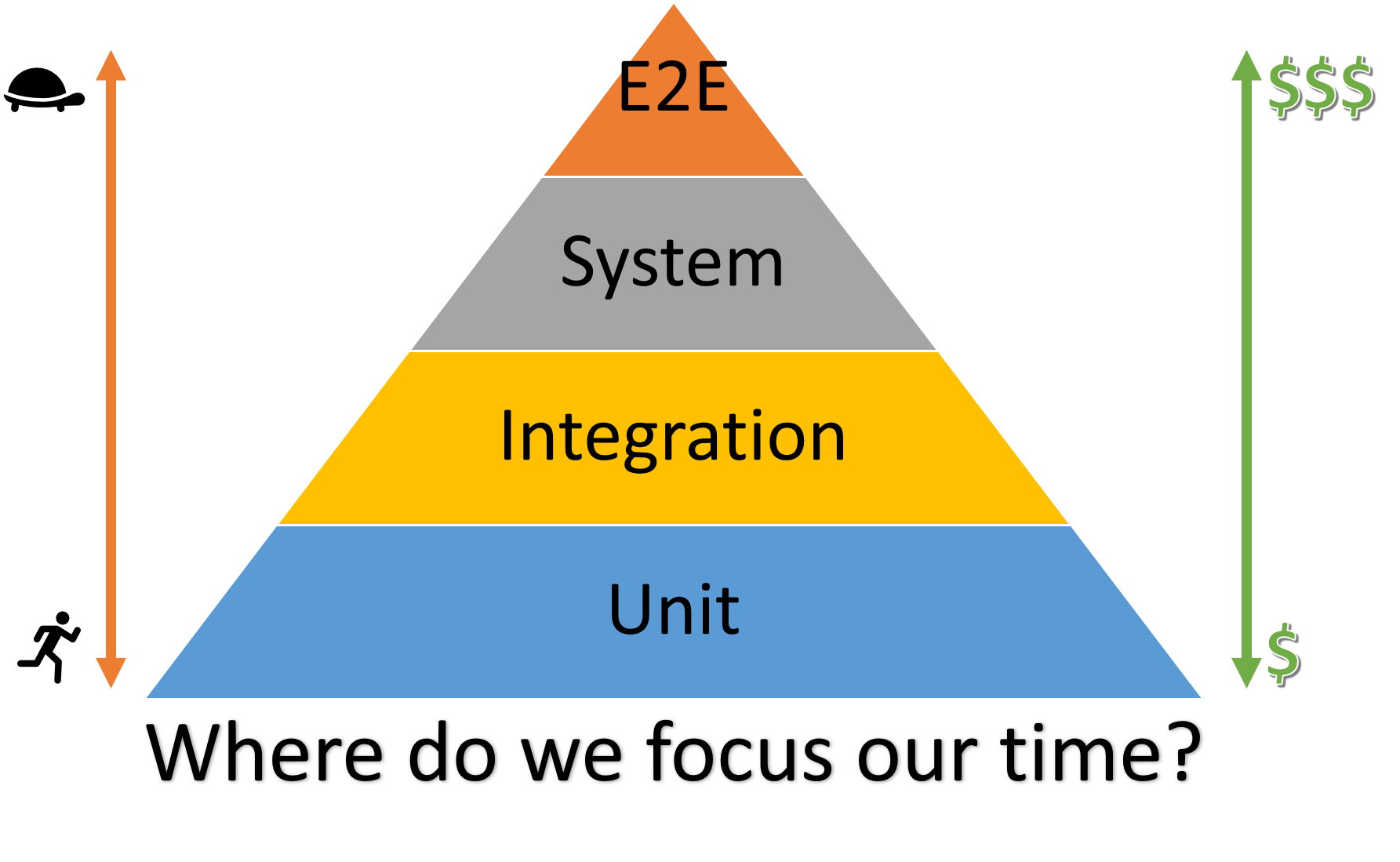
To understand the strategy for testing performance, it is worth reviewing the levels of testing that are typically done for the logic of a program and to understand why they are done:
- Unit Tests: Tests of specific modules (such as files, classes, etc.) of code with controlled inputs and expected outputs.
- Integration Tests: A group of related modules are tested together in order to validate their behavior. This can range from a big piece of software service to a complete input/output test on a single software service which only serves a part of a user request. E.g. the whole flow for user creation might include a call to an “Identify Validation Service”, and an integration test might cover just the call to the “Identity Validation Service” without involving the whole system flow for user creation.
- System Tests: A test on a user-facing business requirement that may involve several micro-services working together. For example, creating a new user account, making a bank transfer to another user, adding a user as a contact, etc.
Why bother with these different kinds of tests? Why not just write all the software and then do the System Test to see if the user would be happy and call it a day? The answer to this question is immediately apparent to anyone who has worked in software and has had to find the cause of a software bug.
Computer programs are in many ways completely unforgiving in a way that most people who are not engineers or scientists can have a hard time appreciating. In normal every day life, people write long messages composed of words and symbols, very much like a computer program is, and the reader figures out the meaning behind that message. A typo here or there is no real obstacle, and the reader can largely figure out what the writer intended. Entire words can be reversed, and the reader will still figure out what was intended.
For example, if someone writes:Jill is turning 8 in July and Sally is 15. Next year Jill will take her driver's exam.
The reader knows that driving is something restricted to older people, typically 16 years or older. Thus, the speaker must have meant to say that Sally will take her driver’s exam next year.
Computers, on the other hand, are terrible readers, they will do exactly what they are told. Imagine if someone writes a program like the following:numItems = 10;
while (numItems > 0) {
doThing();
numItems = numItems + 1;
}
In this case, the computer will start with numItems being 10, then 11, then 12, etc. It will never stop and the program will take up 100% CPU until it is forcefully stopped. A single character error of “+” instead of “-” is all that it takes for this to happen. The code is fully syntactically correct and contains no errors the compiler can detect.
If you run a request at the system level, let’s say to open a new bank account, all you may see is that the system is unresponsive and never creates the account. And if this operation is executing 20,000 lines of code that are interspersed in a system with 20,000,000 lines of code, you are going to have a bad day trying to find that error. However, if a unit test exists for the function in question, the error can be constrained to a single failing test that covers only 20 lines of code.
Lines of code aren’t even the only problem. Often bugs only appear in certain combinations of input and configurations. If your system and user have 200 configuration settings, each of which have 4 different possible inputs, then there are 1,600,000,000 possible permutations of inputs possible. For all practical purposes and intents, writing a system test for every permutation is impossible. However, writing a unit test for each configuration setting can reduce the number of needed tests to as little as 800, which is annoying, but at least it is humanly possible.
Thus, the efforts of a software engineer who is creating tests are roughly arranged as follows:
Performance Testing
Performance testing follows the same basic principles as logic testing, the rule of thumb is that more effort should be spent testing smaller parts of the system, where it is easier to identify the cause of any problem that is found.

Logical testing is focused on assuring, given a specified input, that the system produces the correct output. For example, if a piece of code that produces the positive square root of a number is given the input 16, it should produce the output of 4.
Performance testing, on the other hand, focuses on making sure that the system adheres to non-functional business requirements. For example, if your system is expected to have 1 million users, and each user is expected to send 2 messages per hour, with peak load being 10x higher than average load, then your system that receives and stores messages must be able to handle loads up to 5,555 messages per second.
Performance related business requirements typically fall into a few categories:
- Throughput: How many messages/interactions per second must be processed.
- Latency: The maximum amount of time that a user should wait for a response after making a request.
- Data Retention: The total amount of data that must be stored on behalf of users, and how long this data must be retained.
For example, a bank may end up only having 20 transactions per second, but credit-card companies require a transaction approval/rejection within 2 seconds, and user transactions must be retained for 5 years to comply with taxation laws.
Performance Unit Testing
Because the business requirements are unclear about the performance requirements of specific modules of code, it is actually not as common to do performance testing at the unit-level as one may think. If requirements are known for an individual software unit, then performance unit tests should certainly be created, but in practice, most performance testing ends up happening at the integration and system level.

Performance Integration Testing

At the integration-level, performance testing will typically focus on a software program that is running on a single computer. This allows one to test the following performance bottlenecks:
- CPU Usage
- RAM Usage
- Disk Usage
However, it does not permit realistic testing of:
- Network Usage
- Deployment environment
For services that have an HTTP/HTTPS interface, tools like siege can be used to assess several important parameters including:
- Availability: The error rate on requests. An increase in error rates during a performance tests can often indicate a flaw in how parallel requests are processed, or it can indicate a bottleneck in handling requests, such as waiting for a response from a database.
- Response Time: This is the typical latency for handling requests, which is especially important for services that process requests that come from human users.
- Transaction Rate: This is the total throughput of how many requests can be processed per second, which can often be derived from a company’s business requirements.
- Concurrency: A rough indicator of how many requests were able to execute in parallel. A low level of concurrency can expose bottlenecks in algorithms that were written to maximize the number of parallel operations.
As an example, we will use the siege tool, which was discussed in the previous post Language and Performance: Java and D. The subject of our test will be the software component “funnel-mouth” which is part of the Funnel system to upload data. This service is responsible for ingesting uploaded data, compressing and batching it, and sending it along to “funnel-stem”, where other services will receive that data.
In our test, we use the following siege command:
$ siege -f urls.txt -c200 -b -r25 \ -H 'Content-Type: application/json' \ -H "Authorization: Bearer $ACCESS_TOKEN" The server is now under siege... Transactions: 5000 hits Availability: 100.00 % Elapsed time: 1.01 secs Data transferred:0.01 MB Response time: 0.04 secs Transaction rate: 4950.50 trans/sec Throughput: 0.01 MB/sec Concurrency: 192.18 Successful transactions: 5000 Failed transactions: 0 Longest transaction:0.06 Shortest transaction:0.00
The file “urls.txt” contains a list of local URLs to be called and looks like this:
http://localhost:8080/users/demo/data/funnel/Update POST <file0.json http://localhost:8080/users/demo/data/funnel/Update POST <file1.json ...
In addition, there is a bunch of files that contain randomized data to upload. So “file0.json” contains data like the following:
{
"id": "p0",
"status": "INACTIVE",
"age": 48,
"coord": {
"latitude": 37.662821,
"longitude": -97.367057
}
}
In this particular test, siege was used to simulate 200 concurrent users, each making 25 requests each in order to upload data. We can glean the following information from these results:
- Availability: 100.00% :: Looking sharp, we don’t have any major errors that are only exposed under high load.
- Response Time: 0.04 secs :: It takes 40ms to process each request. The human eye can perceive roughly 30 frames per second (~33ms), which means that this latency could start to become an item of concern if it gets worse, but it is within the boundaries of requirements. If this was worse, we would consider using a profiler to figure out what is taking so long.
- Transaction Rate: 4950.50 trans/sec :: Given that most operating systems start to struggle with as few as 2000 new TCP connections per second, it does not appear that the software itself will be a bottleneck, but rather the network.
- Concurrency: 192.18 :: This is a high number, given that the computer on which the tests were run only has 8 CPU cores. However, this is made possible via the use of Fibers and an asynchronous web server.
So far so good, let’s move on to system testing.
Performance System Testing
The requirements for system testing are often the easiest to define, due to how closely they relate to business requirements. Additionally, system testing will typically be conducted against a staging environment that reflects the production environment as closely as possible. This means that mistakes in the deployment, such as the choice and arrangement of hardware and network topology, will quickly make itself apparent.

Assuming that Performance Integration Testing has been done and that performance goals were met, one’s attention can be directed to the network topology and deployment of the system. Perhaps network latency is a big problem, but there is plenty of free RAM and CPU, thus it would make more sense for a couple of individual services to deployed on the same machine rather than having to communicate over a network with each other. Or, it may make more sense for requests to be batched together and sent in groups of 100 messages rather than one at a time, in order to reduce the number of network requests.
System Under Test
As a practical example, let us run a performance test on the Demo environment of Funnel, which can be seen here. In this demo environment, the allocation of hardware is quite constrained.
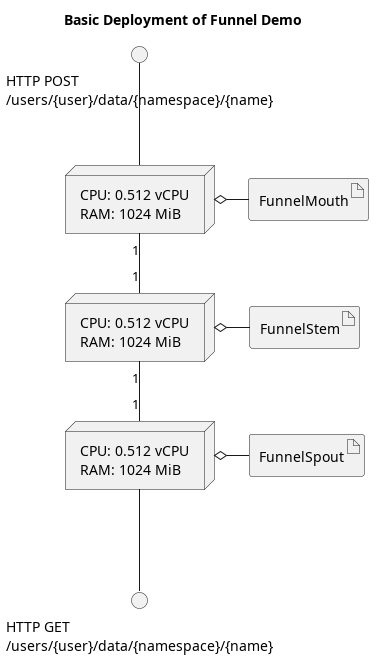
In this system, HTTP POST requests are routed to 1 instance of FunnelMouth via a Load Balancer that splits the traffic. HTTP GET requests are routed to 1 instance of FunnelSpout via a Load Balancer as well. Under heavy load, the system will dynamically scale upwards and add more instances.
Each node has 0.512 vCPUs, which roughly corresponds to half a core (thread) of a CPU. Because the hardware resources are so limited in this environment, it makes for an excellent demonstration of system performance.
Tradeoffs in Maximum Performance
A naive assumption may be that the number of requests a system can handle simply goes up and up as the load of the test goes up until a certain limit is reached. However, performance outcomes in reality are significantly more complicated than this.
For example, as the number of parallel requests being made by a test go up, so too does the amount of resources used by the target system just to accept the requests and change contexts. If a system is receiving more requests than it can handle, then new requests can end up waiting for older requests to complete before they even begin execution.
To make matters worse, it also takes computational resources to receive those incoming requests, whether they can be processed or they have to wait. Thus, the throughput, the number of requests handled per second, can actually go down as the number of incoming requests go up. In extreme cases, a system can become so busy trying to acknowledge new incoming requests, that no CPU resources remain to actually service those requests!
To illustrate this point, let us run a similar performance test as we did with the integration test, but view the results under varying amounts of load.

As before, each test “user” will connect, make 25 requests, and then disconnect. We will vary the number of simultaneous “users” that are involved in the test, and observe the total throughput of the system.
| # of Users | Transaction Rate | Response Time | Concurrency |
| 5 | 56.06 R/s | 90 ms | 4.82 |
| 10 | 102.04 R/s | 100 ms | 9.77 |
| 20 | 132.28 R/s | 150 ms | 19.71 |
| 40 | 119.19 R/s | 310 ms | 37.10 |
| 60 | 113.04 R/s | 470 ms | 53.09 |
With only half a CPU thread available for processing requests, the results aren’t expected to be amazing, but they serve as a demonstration of how performance changes under load. Naturally there are almost always ways to optimize and increase the performance of a system, but sooner or later, a barrier is reached where the cost of each minor improvement becomes infeasible for the business. At this point, tradeoffs must be made.
Let us assume for the sake of this exercise that the software is already at a high level of performance and further improvements would take too long or be too costly for the business. How do we make sense of these numbers?
With 10 vs. 20 simultaneous users making 25 requests each, the total transaction rate goes up, but so too does the response time. While more requests are being accepted into the system to be processed, each request must wait longer to get access to the CPU, resulting in higher response times.
The peak throughput seems to be when the system is handling 20 concurrent users at a time, resulting in a transaction rate of 132.28 requests per second, however, the response time per request is 150 ms in this case. The minimal latency, however, can be found when there are only 5 concurrent users at a time.

While such small servers would rarely be used for a full production environment, it illustrates an important point. Maximizing throughput often involves grouping requests together, perhaps in batches. However, this often comes at the cost of latency. A business has to choose how they allocate their resources. To get lower latency, less load per server instance is needed, which means there must exist more server instances, which increases the cost per request. Depending on the balance between profitability and user experience, a compromise is required at the business level.
Summary
- A software system’s performance will be limited by the tightest restriction on its usage of CPU, Memory, Network, and Disk.
- It is important to understand the theoretical maximum performance to solve a given problem, in order to determine if a program is performant or not.
- Like logical tests, performance tests can be performed at the unit, integration, and system level.
- Performance tests typically focus on throughput, measuring the requests per second, and latency, measuring the time between when the request is made and the response is received.
- Most of the effort in making a system performant is in the selection of algorithms and data structures, but using a profiling tool can help catch unintentional mistakes or false assumptions.
- As systems near their performance limits, there are tradeoffs between throughput and latency, which often translate into tradeoffs between profit and user experience.
4 Responses
First
I’m not sure where you’re getting your information, but great topic. I needs to spend some time learning much more or understanding more.
Thanks for wonderful info I was looking for this information for my mission.
I am not sure where you’re getting your info, but good topic. I needs to spend some time learning much more or understanding more.
Thanks for magnificent information I was looking for this info for my mission.
whoah this blog is excellent i love reading your articles. Keep up the good work! You know, a lot of people are looking around for this information, you can aid them greatly.