Perspectives on Software Performance
Software Quality
In an ideal world, if you give a computer instructions on how to produce results, whether this is to connect a customer with a taxi or to complete a bank transaction, the only thing that would matter would be the correctness of the software algorithm, that is, whether it has correct functionality or not.
However, there are many other factors that influence how software quality such as:
- Security: The world isn’t made of cuddles and hugs, and software must be built with attackers in mind. This is especially true in software where attackers have something to gain, such as in banking.
- Maintainability: The code that is written must be written in a way that those working on it can navigate, maintain, and modify that code.
- Usability: Ultimately software is written for people to use, and ease of use for those people should be a top priority.
- Efficiency: The usage of time, memory, and other computational resources should be as low as possible.
The focus on this article is performance, another way of describing efficiency.
What is Software Performance?
Ultimately there are two ways of thinking about what performance performance means:
- Given a finite set of resources (such as a game console), get the maximal amount of output that is possible from those resources (such as a powerful and fast game).
- Given a finite problem (such as serving 1,000,000 bank customers or a Mobile App), solve that problem using as few computational resources as possible in order to drive down costs, increase battery life.
The usage of resources, such as CPU and Memory can often be approximated very early in the development of a software system, often before the first line of code is even written, and the vague outlines of a problem are being discussed. A rough understanding of the problem and the chosen approach can be enough to catch problems very early.
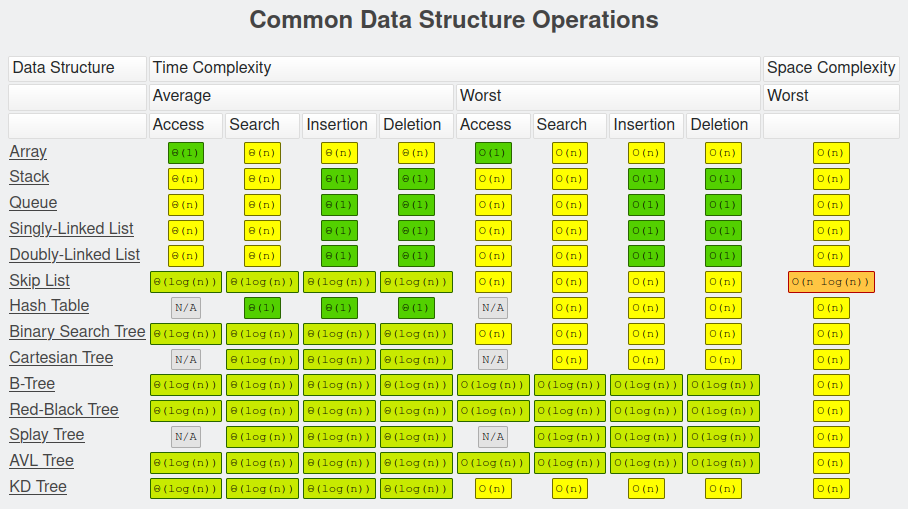
One begins by choosing the resource that your are inspecting, such as CPU or Memory. CPU usage is approximated by looking at how many CPU instructions would have to run in order for an algorithm to complete. The most common way of describing the bounds of performance is using Big-O Notation.
As an example, let’s focus on a concrete problem. Suppose we would like to write an algorithm that, given a list of students which have a score, prints the name of the student with the greatest score.
A naïve approach would be to do the following:
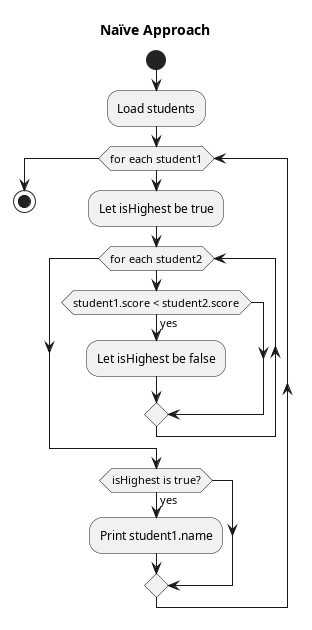
- For every
student1, do the following check:- For every other
student2, do the following check:- Is
student1‘s score greater thanstudent2‘s score?
- Is
- If all other students had a lower score, then print
student1‘s name.
- For every other
While this approach does produce a correct result, it is far from efficient. But first let us take a moment to get a rough idea of its complexity and how to represent it using Big-O Notation.
Suppose that there are “N” students, where N could be 30, 100, or 1000. Clearly, the more students there are, the more work needs to be done to find the one with the highest score.
When one compares two students, their scores are being compared and a few other operations are being done. In most CPU architectures, things like a comparison can be done via a single CPU instruction, such as the Intell x86 Architecture CMP instruction or the MIPS Architecture SLT instruction. As a rule of thumb, most built-in statements in a programming language will translate into a fixed number of assembly language instructions for the CPU.
For the sake of this example, let’s suppose that 6 assembly instructions will be created each time student1 is compared to student2 and the value isHighest is updated. If there are N students in total, that means the total number of assembly instructions run is roughly 6 * N * N = 6 * N2. This algorithm would be described, using Big-O Notation, as being O(N2) with respect to CPU.
To say an algorithm is O(N2) means the following: There exists two constants, C1 and C2, such that the actual number of CPU instructions executed is between C1 * N2 and C2 * N2. So in our example above, if C1 was 5 and C2 was 7, then this condition would be true.
The purpose of this notation is the reduce the amount of work it takes to estimate how much the algorithm costs. You may not know exactly how many assembly instructions your compiler creates per line of code, you may not know how many lines of code will happen each step, but you do know roughly how many times your loop runs. This algorithm checks every student (N iterations), and for each student, it compares it against every other student (N iterations). Thus, the number of CPU instructions run is some multiple of N2, which is written as O(N2).
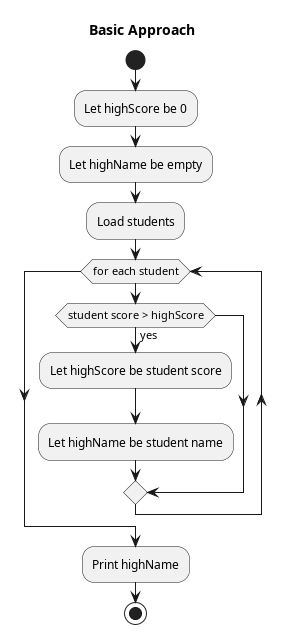
To complete this example, one could very easily solve the same problem with fewer computational resources with an algorithm like the following, which has a complexity of O(N):
- Let the
highestScorebe 0. - Let the
higestNamebe empty. - For each
student- If their
scoreis greater than thehighestScore - Then set
highestScoreto their score andhighestNameto their name.
- If their
- Print the
highestName.
Why Performance Matters
It is not uncommon to hear software engineers making the argument that time spent on software performance is not useful, and that not much attention should be paid to such concerns.
The typical argument is that high performance is not relevant in industries like banking or transportation, because computers are far more powerful than they were in the past, and such concerns are only relegated to specialized industries like game development, where engineers try to squeeze as much out of their hardware as they can.
In all of my experience, no matter the industry, such short-sighted thinking lead to problems in short order. These problems can manifest in many ways:
- Inefficient algorithms, such as those with Big-O N3 complexity or worse, can quickly cause systems to collapse as the number of users and system load picks up.
- Inefficient memory usage and inefficient CPU usage increase the number of machines needed to support the load, greatly increasing costs.
- Inefficient algorithms and structure require more complex algorithms and architecture later on, as the system must divide information and load between multiple computers.
Early decisions in system design can have long-term consequences which are hard to change later on. The changes to the system made in response to growing load are rarely given careful consideration, as they are frequently implemented during an emergency so severe that it can no longer be ignored. The ultimate result is a system that becomes increasingly complex, hard to work with, and costly in both hardware and engineering-hours needed to make changes.
With that being said, making efficient performant programs does not automatically translate into short-term savings either. The reason for this is that programs do not run in isolation on a hypothetical computer. and one does not necessarily pay only for the RAM/CPU that you use. From a cost perspective, even an efficient algorithm does not produce any savings if you are paying for an entire computer no matter what runs on it.
Cloud Computing and Containerization
A major change in the software industry over the past two decades has been the shift towards cloud based computing resources like Amazon ECS, Google Cloud, Kubernetes, or Microsoft Azure. In each of these systems, software is wrapped in a software container, using systems like Docker, and declares how much CPU and Memory it will need. The container orchestration software (e.g. Kubernetes), has a set of computers at its disposal, and it automatically selects which computer to deploy and run that software on, and exposes a uniform interface such that all these computers behave as if it was one larger system, commonly referred to as a “cloud”.
So how does all this relate to being efficient or saving money? The reason is that with almost no extra development costs, multiple services can run on the same computer. In theory one can also organize your computers and decide which services run on which computers, but it introduces a host of additional problems that complicate maintenance and deployment. This complexity resulted in many companies simply deciding to put no more than a single service per computer. With the advent of container orchestration software, the deployment and maintenance costs go away, but the full benefit of running multiple services on the same computer remains.
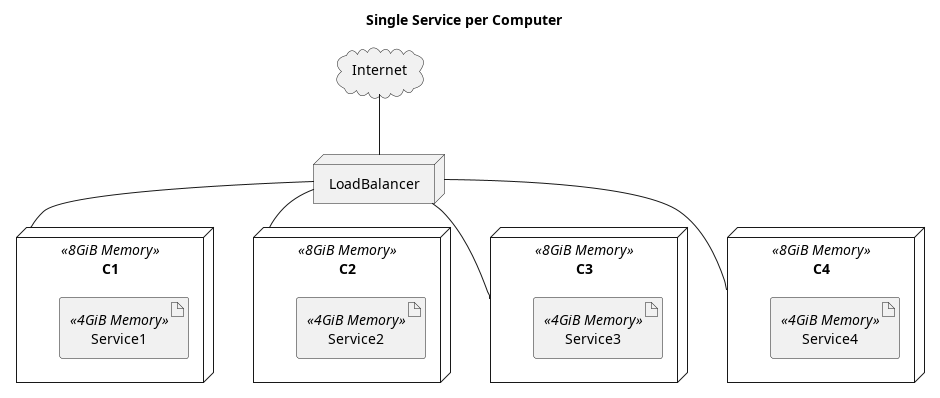
Imagine a company has a number of computers, each of which has 8 GiB of RAM and suppose there are many services the company runs, each of which only really needs 4 GiB of RAM. By running 2 services per computer, the company only needs 1/2 as many computers to run the same number of services as it did before, which is a significant cost saving.
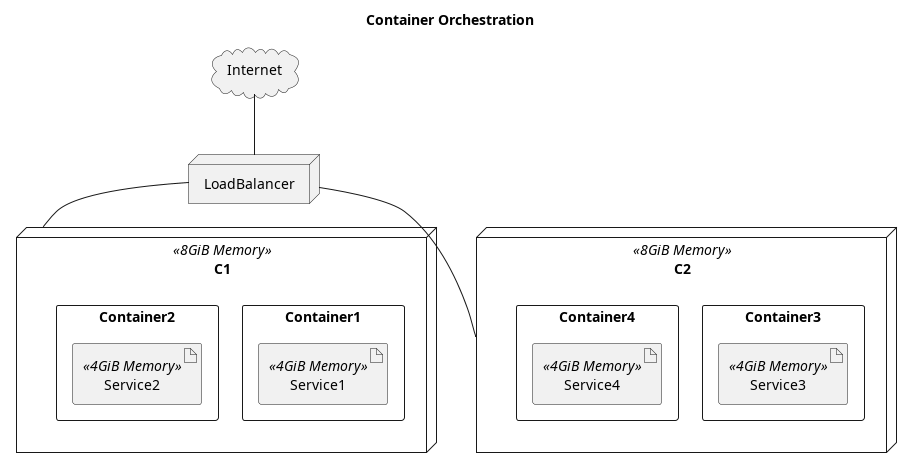
This is where performance and efficiency come back into the picture again. The old argument that performance doesn’t matter, because computers are so much more powerful, is no longer valid. With container orchestration, resources saved on one service can be used by another.
Let us revisit the example above, of a company that cut its computer costs in 1/2 by running 2 services per computer. If the algorithms and technologies utilized to write their services took only 2 GiB of RAM instead of 4 GiB, then 2 times as many services could run on a computer. The scale of savings would be just as significant as the scale of savings gained by moving to cloud computing and container orchestration.
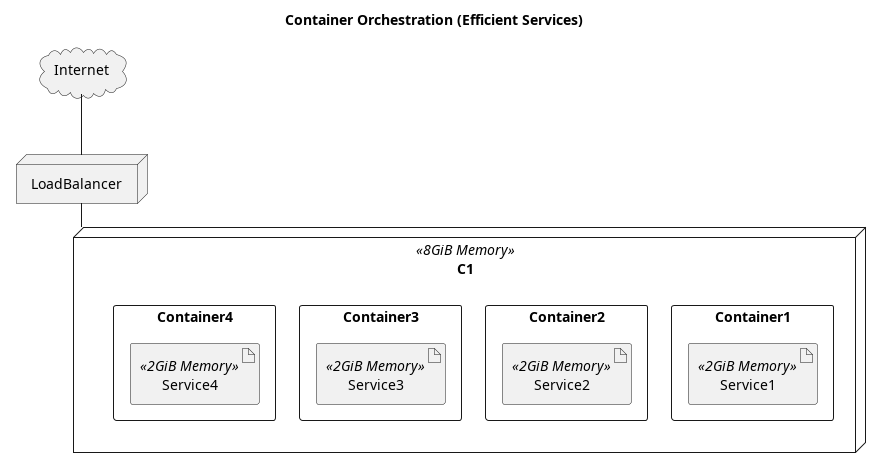
Thus, in the world of cloud computing, efficiency can generate significant savings by increasing the number of services that can be run on a single computer.
What’s Next?
In a future article, we will take a look at ways to make software more efficient beyond the choice of algorithms, and discuss how the choice of programming language can have a significant impact.
2 Responses
This blog is really good, easy to understand and informative.
Glad to hear that it could be of use!